


STATISTIQUES ETENDUES CANABLOG sous WORD + ACCESS
STATISTIQUES ETENDUES 
CANABLOG sous WORD + ACCESS (V6)
1 Quelles sont les difficultés ?
1.1 Pourquoi Canablog ne traite pas en historique complet
1.2 Format Canalblog "Derniers accès"
1.3 Les Codes de Champs de WORD
1.4 Visual Basic / Macros
1.5 Le moment de consultation
2 Principe de réalisation
2.1 Les champs Canalblog retenus
2.2 Les conditions de logiciels et matériels
2.3 Le transfert des informations Canalblog
2.4 La Macro WORD
2.4.1 Exécution de la macro
2.4.2 Les anomalies de table de la macro
2.4.3 Les anomalies N/A ou absence d'image
2.4.4 Le déroulement logique dans la macro
2.5 Le passage dans ACCESS
2.5.1 La Requête de recherche des dernières dates entrées
2.5.2 Un Exemple de requête standard 7
2.5.3 La régénération des codes pour un affichage en clair
2.6 Le suivi dans EXCEL
2.7 Installation de la Macro dans WORD
3 Conclusions
2ème PARTIE
4 Statistiques Complètes
4.1 Les problèmes liés à la dernière zone Provenance/Pages
4.2 Les tables à gérer
4.3 Le dépouillement des données
4.4 Les améliorations
4.5 Le déroulement des opérations
4.6 La mise en place de la macro
4.7 ACCESS
4.8 Quelques exemples sur ACCESS
4.8.1 Nouvelles Tables ACCESS
4.8.2 Requêtes ACCESS
4.8.3 Requête de recherche d'erreurs ou d'oublis
4.8.4 Requête de recherche des dernières données entrées
5 Conclusions de la version complète
6 Quelques résultats
7 Suivi des Modifications
8 Un repérage étrange
Si vous arrivez directement sur cette page par un moteur de recherche, vous pouvez avoir accès à la table des matières et à chaque article, en page d'accueil. L'accès se fait par l'un des deux liens en tête de colonne de droite ----->
ATTENTION à compter du 15/09/2019 les commentaires ne seront plus possibles à causes de quelques imbéciles qui font du spam pour le plaisir de nuire ! désolé !
Préambule
Depuis 9 mois (!) que mes deux blogs bricolsec et lokistagnepas existent, ceux-ci sont en vitesse de croisière, et je considère qu'ils sont bien lus maintenant (du moins cela est ma vision).
J'aurais bien aimé à mes débuts pouvoir croiser tous les résultats pour progresser un peu plus vite, mais je n'ai jamais pris le temps de le faire, car la "substance" même des blogs me paraissait (et reste cependant) plus importante.
Maintenant que j'ai un peu plus de temps, j'ai pris la peine de m'y atteler, et c'est donc chose faite.
Cela a pris "un certain temps" car la mise au point n'est pas trop facile.
1 ère PARTIE
1 Quelles sont les difficultés ?
Ce paragraphe explique finalement pourquoi cela a été si difficile de faire quelque chose.
1.1 Pourquoi Canablog ne traite pas en historique complet
En réalisant cette chaîne de mise en forme et stockage de données, je me suis réellement aperçu du volume de données important à stocker. Aussi, bien que je le regrette, je comprends mieux pourquoi Canablog se limite aux 100 derniers accès par blog, mais….lorsqu'il faut stocker plusieurs fois par jour pour tout avoir c'est lourd à gérer…et j'ajoute maintenant que ce n'est plus possible.
Pour un exemple, la totalité des 5 pages de statistiques en "derniers accès", recopier CTRL+C +CTRL+V sous WORD représente :
12670 Caractères espaces compris,
900 lignes
500 paragraphes
737 KO pour la taille du fichier WORD (*.DOC)
Si on multiplie 12670 caractères par 365 Jours (en supposant 100 visites par jour), cela fait tout de même 4.62 MO par année et par blog. (Sachant qu'il y a à ce jour 437752 blog chez Canalblog, cela ferait du volume…). Il me semble exclu je pense, de faire un fichier WORD chaque fois qu'il y a 100 visites.
(Ce serait dommage de se réveiller en pleine nuit pour faire cela !)
Les statistiques offertes en page de synthèse ne me sont pas vraiment utiles, car elle ne reflètent que l'audience, et ne permettent pas de refaire le point sur les visites multiples, ni les pays.
En format EXCEL au format *.CSV, chaque ligne va en totalité dans la première colonne.
Pour l'intégrer il faut renommer le fichier *.CSV en *.TXT. (Avec mes vieux logiciels)
Le format TXT est quand à lui très simple mais ne contient que trop peu de données.
Dans les statistiques, à l'extrême limite, je dirais que l'Operating System ne m'est pas réellement utile. Le navigateur l'est un peu plus, car suivant ceux-ci, quelques artifices ne fonctionnent pas. Mais pour 4 caractères de plus je garde tout !
Encore une modification de dernière seconde, car mes vieux logiciels on considéré l'année 08 comme année 1908 ! Eh oui, je vais devoir corriger ce vieux problème qui n'en finit pas ! N'est ce pas Canablog ? Et en 2099 ? C'est loin ?!? Serez vous tous là ? Moi pas !
1.2 Format Canalblog "Derniers accès"
Le tableau "OUTILS / STATISTIQUES / DERNIERS ACCES" est bien lisible, je l'apprécie bien, et il contient beaucoup d'éléments.
Pour une exploitation ultérieure par copier coller, les images qui sont très utiles en examen rapide à l'écran, compliquent sérieusement les choses pour créer une base de données.
Il faut donc partir de cette table des "derniers accès" et travailler en copier coller. Il faudra ensuite remplacer les images par des codes exploitables de préférence sous ACCESS (ou éventuellement sous EXCEL, mais c'est moins pratique).
Dans cette optique on peut espérer une taille réduite au minimum.
Ainsi les chiffres indiqués plus haut se résument à :
4692 Caractères espaces compris
100 lignes
100 paragraphes
5 KO pour la taille du fichier au format TXT
Il y a donc une réduction très importante de la place occupée (dans le format défini dans les paragraphes ci-après)
1.3 Les Codes de Champs de WORD
Le tableau ou les différentes pages ajoutées à la suite constituent au niveau de WORD un seul tableau (c'est une chance !)
Le fichier ainsi formé sous WORD est donc un tableau contenant à la fois du texte et des images qui correspondent au Pays, au Navigateur et à l'Operating System.
Les images sont incluses dans des codes de champs, de même que les liens (Hyperlink).
(Pour ces derniers, on le verra plus loin, bien que cela soit très utile, le volume en est trop important en termes de caractères. De plus le lien est cliquable sous Canalblog, mais il est souvent incomplet à l'écran faute de place. Il reste exploitable tout de même car le lien transmis est complet).
Mais cela étant les cas sont très nombreux à traiter et pour l'instant, je vais  me contenter du minimum acceptable. Ceci veut tout de même dire que la taille est encore plus importante que ce que l'on voit à l'écran !
me contenter du minimum acceptable. Ceci veut tout de même dire que la taille est encore plus importante que ce que l'on voit à l'écran !
Alors, les codes de champs ! Eh bien toute la difficulté est là, car à moins d'être positionné sur les deux marqueurs {} de début ou de fin, on ne peut pas supprimer ces marqueurs sans TOUT supprimer.
Les possibilités offertes alors restent minces. Ceci concerne principalement les champs {INCLUDEPICTURE …..MERGEFORMATINET}.
Pour les champs {HYPERLINK ….}, il serait possible de les supprimer en se positionnant sur le début de champ, mais il n'est guère facile de repérer la fin du champ, car c'est une donnée qui varie à chaque fois, puisque c'est une adresse IP.
On comprendra dès maintenant que le dernier champ Canalblog de "PROVENANCE / PAGE VISTEÉ" fera les frais de ces difficultés, d'autant plus que du point de vue de la place occupée, cela reste le plus conséquent. Il faudrait codifier et restituer en BD...
Pour des statistiques vraiment exploitables, il y a déjà pas mal à faire avec ce que j'ai sélectionné comme champs Canalblog. (Voir ci-Après)
1.4 Visual Basic / Macros
Cela ne concerne que moi, mais autant je peux me lancer dans des langages Assembleurs, Pascal (de préférence) voire en C, autant j'ai une répugnance pour Visual Basic qui est pour moi une montagne de mots clé, pas toujours explicites.
J'ai donc fait le strict minimum, et je dois reconnaître que c'est tout de même pratique, mais il faut en faire tous les jours pour rester dans le bain !
(J'ai la nostalgie des bons vieux fichiers .BAT, avec les paramètres et/ou réponses que l'on pouvait faire suivre)
D'ailleurs je ne sais pas automatiser du début à la fin. Il y aura donc quand même quelques opérations manuelles…
1.5 Le moment de consultation
Ainsi qu'il a été préalablement évoqué, le temps entre récupération des 100 dernières consultations, dépend de l'activité. Cela signifie qu'il n'est pas possible d'attendre les 100 suivants, mais que si l'on consulte à un instant donné, on traite CE QUI NE L'A PAS ENCORE ETE FAIT.
En d'autres termes, il faut récupérer une quantité VARIABLE d'informations, depuis la dernière récupération.
La procédure devra donc être indépendante du nombre d'éléments de façon automatique, (et le sera).
Il ne sera cependant pas possible de gérer un "overflow" non prévu (cas d'une brusque augmentation de trafic, les données passées seront irrémédiablement perdues -sans changement d'ailleurs-).
Cela ne résoudra pas non plus le problème en cas d'absence.
2 Principe de réalisation
Copier depuis Canalblog les lignes qui sont nécessaires (du dernier stockage +1 jusqu'à cette minute), dans une fenêtre WORD (sans spécifications de fichier particulière, voir recopie écran § 1.3)
Exécuter la macro A_MACROBLOG1 (lien pour téléchargement en § 2.7) Vous pouvez avoir plusieurs blogs et donner ainsi une possibilité complémentaire permettant de gérer l'ensemble des blogs dans une même Base de Données. (2 caractères). A la conversion du fichier, répondre "Texte brut" et le travail est terminé.
Pour les images qui ne sont pas encore répertoriées en table de la macro, il faut ajouter les éventuels codes et refaire une sauvegarde (Le nom obligatoire est BLOGSTAT.TXT). Il faudra aussi ajouter dans la macro les codes correspondants (si vous le désirez).
2.1 Les champs Canalblog retenus
Pour des questions de taille de stockage prévu pour plusieurs années, il est nécessaire de garder seulement le strict nécessaire. Pour ma part, j'ai gardé :
Date
Heure
Nav.
Sys.
Résolution (SUPPRIME)
Pays
Adresse IP (CONSERVE mais SANS le LIEN)
Provenance / Page visitée (SUPPRIME)
Le principe étant établi, vous pourrez éventuellement modifier les zones qui vous intéressent. (Ce ne sera pas trop simple cependant, si on ne maîtrise pas parfaitement Visual Basic et les Macros)
Notamment le champ Provenance est composé en réalité de deux champs distincts (avec fin de ligne imposé).
A été ajouté un champ de 2 caractères du code de blog à la place de la résolution d'écran qui me semble moins importante.
A remarquer sur ce sujet, que je ne recherche pas des prouesses techniques de pointe, mais au contraire, diffuser sous un aspect "agréable" mes connaissances. Dans ces conditions, ce champ ne m'est pas absolument nécessaire, mais chacun pourra agrémenter à son idée...
Pour Provenance / Page Visitée, c'est une question de choix de taille. J'ai souhaitée ma BD sur plusieurs années, donc je renonce pour l'instant à ce champ trop long. Il faut être un peu économe !
2.2 Les conditions de logiciels et matériels
- CANABLOG en l'état au 08/04/2008
- WINDOWXP 2002 SP 1, PENTIUM 4, 2.6 GHZ, 512 MO
- WORD 2002
- ACCESS 2.0
- EXCEL 5.0
2.3 Le transfert des informations Canalblog
Ouvrez WORD (nouveau fichier ou n'importe quoi) ET CANALBLOG.
Utiliser le menu OUTILS / STATISTIQUES / DERNIERS ACCES. A ce stade commencer à sélectionner le texte comme indiqué sur la recopie ci-contre.
Vous irez ainsi jusqu'à la cinquième page si nécessaire, et en tous cas pas sur la dernière date (ni en dessous) de votre fichier dernièrement stocké. (Ici votre dernière date de stockage serait 08/04/08 13:37:38 pour le blog considéré)
Vous procéderez par CTRL+C dans Canalblog et CTRL+V dans WORD (à priori ça suit tout seul)
C'est tout ! Je n'ai pas de possibilités d'automatisation d'autant qu'il faut obtenir les dernières dates heures, minutes, secondes du dernier stockage (on verra dans ACCESS)
A ce stade le travail est terminé au niveau de Canalblog.
2.4 La Macro WORD
2.4.1 Exécution de la macro
Cette macro est réellement le cœur de ces statistiques, car le reste des opérations reste simple et consiste essentiellement en quelques opérations manuelles.
Mon article se limite à la description et à la mise en œuvre, mais il ne peut pas déborder sur la formation à WORD, pas plus qu'à celle d'ACCESS.
Je ne connais pas suffisamment pour assurer une formation, et ce n'est pas mon souhait. Il doit rester à César ce qui lui appartient ! Chacun son domaine !
Mise en œuvre de la macro :
Faire ALT F8 ou par le menu OUTILS / MACROS / MACROS et sélectionner "A_MACROBLOG1" puis EXECUTER.
Donner les deux caractères de code de Blog (pour moi BRicolsec ou LOkistagnepas par exemple).
La macro se déroule toute seule jusqu'au stockage sous forme de fichier TXT dont le nom "câblé dans la macro" est BLOGSTAT.TXT.
A la fin de l'essentiel de la mise en forme, la macro demande le type de fichiers et il faut répondre "Texte Brut".
A ce stade il vous reste la possibilité d'examiner "verticalement" les anomalies éventuelles. Et il peut y en avoir de temps à autre…Pourquoi ?
Si tout est OK, FERMER ce fichier BLOGSTAT.TXT et aller dans ACCESS.
Sinon voir ci-dessous. (Vous pourrez télécharger cette macro au paragraphe 2.7 "Installation de la macro")
2.4.2 Les anomalies de table de la macro
Tous les pays ne sont pas rentrés dans la macro et dans le cas où un pays ne figure pas, il y aura une suite de deux ";;" en séparation. Vous pouvez sans problème laisser ainsi, ou au contraire rentrer ce qui manque dans le fichier TXT encore sous vos yeux.
Vous devrez dans ce cas enregistrer vous-même la modification dans le fichier TXT ou dans la BD.
Il y a les Pays, mais il y a aussi les navigateurs et les Operating System…
Tout n'est pas dans la macro, car il y a plus 2 ou 300 pays, et quelques dizaines de navigateurs et d'O/S.
Vous devrez ajouter de préférence les pays qui viennent souvent sur votre blog. Pour les O/S et les Navigateurs, c'est déjà beaucoup moins fréquent.
(A remarquer que Canalblog utilise parfois la même image pour des O/S différents !)
Quand vous avez identifié par exemple un pays absent de la table (voir dans le listing), il vous suffit d'aller dans Canalblog avec click droit sur l'image concernée et d'ajouter le nom de fichier obtenu ainsi chez Canalblog (nom en .png ou .gif) à la macro.
Le deuxième code sur ces lignes de la macro correspond à ce que vous voulez comme valeur dans votre BD. Gardez toujours des mnémoniques, c'est plus facile. (Pour les pays ce sont les codes de pays reconnus mondialement)
Si vous avez ajouté des lignes sur les 50 existantes, ne manquez pas de modifier la constante ZONE1 qui a déjà évolué à 60
(A ce stade vous pouvez préparer des lignes avec ZZ qui n'existera jamais, et vous aurez ainsi assez facile de remplacer ces ZZ tant dans la première zone que la deuxième ou dans la dernière zone -zone en désordre Pays O/S et Navigateur- attention aux suffixes différents -png ou gif-).
2.4.3 Les anomalies N/A ou absence d'image
De même, ce cas se produit parfois, et le texte "N/A" (Not Available ?) suivra simplement dans la BD. Ce cas se traite tout seul sans aucune intervention. L'absence totale d'information (vide) perturbera, et le code de blog sera ajouté à la place. Ces caractères sont simplement inscrits dans la zone correspondante pour la BD. (Ce cas ne devrait pas se produire).
Pour l'adresse IP, seule l'adresse est conservée et non le lien (le lien Hyperlink est détruit uniquement lors de la recopie en format TXT). Cette suppression se réalise automatiquement par le passage en fichier Texte.
"La nature" faisant bien les choses parfois, tout est supprimé sauf l'adresse IP qui reste ! C'est ce qu'il fallait !
2.4.4 Le déroulement logique dans la macro
Voici les phases clef qui se déroulent dans la macro. Ceci vous permettra en plus de quelques commentaires de suivre ce qui se passe.
- Introduction du code du blog (2 caractères). (Permet encore de ne rien écraser au besoin)
- Sauvegarde du tableau collé depuis Canalblog, au format WORD sous le nom câblé BLOGESS.DOC sous le répertoire en cours
- Passage en option "sans code de champs"
- Suppression dernière colonne
- Suppression des données de la colonne "provenance/page visitée"
- Conversion de tableau en texte
- Passage en option Affichage des codes de champs
- Recherche des champs à modifier (tous confondus pour un total de 50 à ce jour)
- (Les champs sont constitués du nom de fichier Canalblog (*.png ou *.gif) et du nom destiné à la BD. L'ensemble est constitué respectivement dans cet ordre et dans un tableau TBL à 2 dimensions.
- Passage en options "non affichage" des codes de champ
- Mise en place du code Blog dans la colonne de la résolution ainsi que dans les colonnes vierges.
- Suppression du dernier return qui perturbe
- Ajout de "20" à l'année pour avoir une "vraie date à 4 chiffres"
- Suppression des éventuels espaces.
- Sauvegarde au format TXT sur le fichier "câblé" BLOGSTAT.TXT (répondre texte brut)
- Le fichier est rappelé à l'écran pour vérification. Si OK le FERMER, sinon CORRIGER éventuellement directement ce fichier, L'ENREGISTRER et le FERMER.
(Reprendre éventuellement tout de suite la macro avec le fichier d'origine qui est toujours présent BLOGESS.DOC et relancer la macro et boucler ainsi.)
- Quitter BLOGSTAT.TXT ou WORD (Téléchargement macro en § 2.7)
2.5 Le passage dans ACCESS
Le fichier BLOGSTAT.TXT devra avoir été FERME dans WORD, c'est IMPÉRATIF pour une question d'accès au fichier. (Vous pouvez aussi quitter WORD directement)
- Choisissez votre base de données habituelle, et ouvrez la sur l'onglet "TABLES".
- Choisissez ensuite IMPORTER / TEXTE DELIMITE / TEXTE (délimité)
- Dans la nouvelle fenêtre choisir L'unité de disque, le répertoire et le fichier qui est OBLIGATOIREMENT BLOGSTAT.TXT, puis IMPORTER.
- Dans la fenêtre suivante préciser la première fois "TABLE à CRÉER" et les autres fois "AJOUTER à la TABLE". Précisez également le nom choisi la première fois comme pour les autres. (ne PAS préciser les noms de champs) Il est préférable de créer préalablement cette table avec les longueurs de champs les plus adaptées. Sinon renommer la table et la reprendre en correction pour les noms de champs ainsi que les tailles et les types d'éléments.
(Voir le projet de définition de la table ci contre)
Il est recommandé d'ajuster la taille des champs à ces valeurs. Deux champs complémentaires sont également ajoutés (voir listing des champs qui sont CODE et Divers) et à discrétion d'utilisation.
2.5.1 La Requête de recherche des dernières dates entrées
Cette Requête vous permet avant d'aller récupérer les données sous Canalblog, de savoir pour chaque blog quelle était la dernière date/heure entrée et donc de pouvoir exclure de la capture des données situées à partir de cette date/heure. Voir la recopie ci-contre.
A remarquer deux éléments importants qui sont la notion de date et heure dans les champs correspondants, ainsi que la notion associée DATE+HEURE qui ne peut pas être dissociée sous peine de réaliser des opérations totalement fausses.
C'est une notion de temps et non pas seulement de jours ET/OU d'heures.
2.5.2 Un Exemple de requête standard

Voir l'exemple ci contre qui permet un simple tri sur le pays, l'adresse IP et la date et l'heure.
Voir à côté le résultat de la requête.
2.5.3 La régénération des codes pour un affichage en clair
C'est toute l'utilité des Bases de Données Relationnelles. Vous allez pouv oir régénérer les noms des pays en clair et sans occuper de place dans les fichiers, simplement en ajoutant quelques petites tables.
oir régénérer les noms des pays en clair et sans occuper de place dans les fichiers, simplement en ajoutant quelques petites tables.
Il vous suffit de créer une seule fois les tables correspondantes avec 2 colonnes qui correspondent pour l'une au code, et pour l'autre à son développement en clair.
C'est réellement très bien, mais je n'en dit pas plus car c'est ACCESS dans toute sa dimension, et ce n'est plus mon sujet.
(Bien faire la relation des tables avec la flèche du bon côté -jointure- !)
2.6 Le suivi dans EXCEL
Cette possibilité est exploitable, mais me semble moins adaptée qu'une structure de BD. J'ai essayé et il est tout à fait possible de charger un fichier TXT, mais plus délicat d'ajouter à la suite. J'ai cependant essayé avec pour l'ajout la méthode du CTRL+C et CTRL+V ! Et ça marche, curseur dans la cellule de gauche seulement, et je suis surpris de ne pas avoir à repréciser le type de séparateur.
Il faut remarquer que la première fois, il y a lieu de rentrer comme séparateur le ";". Il y aura certainement à créer, suivant le format, une fonction de date autorisant les calculs complets de date-heure.
2.7 Installation de la Macro dans WORD
Le fichier MACROBLOG1 format TXT est joint à cet article. Cliquer sur ce nom de fichier pour l'obtenir. (click droit pour l'ouvrir dans une autre fenêtre ou l'enregistrer directement dans votre machine sous le nom que vous indiquerez). Ce fichier contient la macro en source.
Pour le chargement en zone macro procéder ainsi :
- Dans WORD charger MACROBLOG1.TXT, sélectionner la totalité du texte par CTRL+C
- Aller ensuite sous OUTILS / MACROS. S'il y a déjà des macros, prendre la dernière macro en modification. Aller en fin d'écran et COLLER ce qui provient de MACROBLOG1.TXT.
- A ce stade enregistrer cette fenêtre et la fermer pour retourner sous word.
- Faire ALT F8 pour vérifier que vous avez bien la macro A_MACROBLOG1 et ANNULER
- C'est fini pour l'installation !
- Arrangez vous pour que cette macro soit la première dans la liste car vous allez l'utiliser souvent ! (c'est pour cela qu'il il y a le "A_")
3 Conclusions
L'article est fort détaillé à mon sens et si vous ne savez pas trop faire, ça devrait bien se passer tout de même, en lisant et relisant attentivement.
Je pense que cette vision de suivi est utile, et il est cependant un peu dommage que Canalblog ne fasse pas un volant de fichier circulaire à peine plus grand.
(Je recommanderais en ce sens un stockage dynamique adapté au trafic de chaque blog, permettant 2 à 4 jours de stockage).
Cela me convient cependant dans mon application et surtout qu'il n'y a pas de développement particulier sous Canalblog. On reste dans le mode le plus commun des blogs qui est : MODELE STANDARD !
Si vous avez des velléités de stocker toutes les zones, il ne tient qu'à vous de lire la suite de cet article...J'ai effectivement continué durant la première version et cela est développé dans la deuxième partie.
Il est tout à fait possible que ce qui est indiqué pose quelques problèmes dans des versions de logiciels différentes, mais le principe devrait rester et sera à adapter...Désolé je n'ai qu'une seule machine qui n'est pas à la pointe du progrès !
En conclusion de cette première partie je méditerai le dicton qu'il ne faut jamais dire "Fontaine je ne boirai pas de ton eau..." car après une lourde mise au point je viens de traiter la version complète. C'est la deuxième partie
2 ème PARTIE
4 Statistiques Complètes
4.1 Les problèmes liés à la dernière zone Provenance/Pages
Je savais parfaitement que vu la structure de la zone PROVENANCE/PAGE cela allait poser des problèmes peut-être délicats à résoudre pour un novice en VB (Visual Basic) et langage Objet.
Dans cette zone se trouvent dans une forme peu intéressante des quantités de renseignements pas tous utiles aux statistiques.
Certains renseignements spécifiques Internet sont de fait souvent doublés par un code de champ.
Autre écueil cette fois, celui d'une foule de visiteurs tous très différents les uns des autres avec des conventions très disparates. On trouve chez certains moteurs de recherche des points-virgules en séparateurs de paramètres…Pas de chance ! Chez d'autres, des %...
Chez d'autres la simple quotte "se trouve modifiée en \" etc…
En ce qui concerne la provenance/destination, il y a parfois des choses étranges avec "Provenance inconnue" pour la totalité Provenance/Page.
Je serais tenté de conclure que la destination n'existerait pas ? Étrange ! Ce cas est pourtant fréquent et comme on n'y peut rien du tout, il ne sera pas considéré comme une erreur.
Pour des questions d'occupation de mémoire de masse et de facilités de recherches ultérieures, il est nécessaire de tout codifier pour éviter de faire des montagnes de caractères inutiles à stocker.
J'ai admis un grand principe de créer 2 zones complémentaires de stockage, de 4 caractères chacune, par ligne de visite. Cela permettra d'exprimer la provenance et la destination (pages visitées)
Cela fait 8 caractères de plus que dans la version précédente ! Cela me semble encore acceptable.
Dans les anomalies, on rencontre la dénomination de mes propres articles qui contenaient des caractères gênants tels que les guillemets ("), les slashs (/ ou \).
Donc avant toutes choses il vaut mieux mettre un peu d'ordre chez soi !
soi !
Dans l'utilisation de WORD, il y a toujours des phénomènes bizarres qui se produisent, notamment des espaces ajoutés ou le dernier return du texte. Il faut bien évidemment traiter.
Il faut aussi reconnaître qu'exploiter ces informations directement en programmation C ou autre est un travail que je refuse de faire, car trop important.
Encore une dernière explication, il ne m'est pas possible de fabriquer un fichier avec les signes des codes de champs (en recopie et option impression cela est peut-être possible mais je n'ai pas réussi). Voir la figure capturée ci contre. (Les séparations en pointillés bleus sont seulement là pour indiquer chaque ligne d'origine Canalblog)
4.2 Les tables à gérer
Pas de miracle, ce qui n'est pas développé se traduira par des tables à mettre à jour dans la macro, ET dans ACCESS, et nous allons toutes les examiner.
Il y a toujours les tables inchangées des Pays, (Operating System et Navigateur si cela vous intéresse), cela reste inchangé.
Il y a en plus, dans la routine de "démontage" des Hyperlink, une petite table fixe des codes spéciaux recueillis et qui permettront la séparation des données utiles.
Les deux principales tables ajoutées ont été séparées entre Provenance et Pages visitées. Pour des questions de durée d'exploitation, il était préférable de procéder ainsi, et d'ailleurs, cela ajoute un peu plus de clarté. Remarquez que chaque table est elle-même séparée en deux tables distinctes (impossible hors VB Objet d'avoir des zones de nature différentes). Il y a donc un code numérique qui sera transmis au final et le code de comparaison alpha qui servira à la comparaison.
On remarque que la table des Pages est assez stable et évolue lentement (au rythme de vos articles), alors que la table de provenance est plus régulièrement incomplète.
Ces manques sont toutefois compensés par un code zéro (Tblprov(1) qui permet de traduire les inconnus en table sans arrêter le traitement.
Attention la comparaison comporte également tous les caractères ASCII et les minuscules/majuscules ne sont pas identiques.
(Ne pas confondre le MESSAGE Canalblog ("Provenance inconnue" valeur de code=2) et le fait de n'avoir pas pu interpréter la provenance à l'aide de la table (Code inconnu valeur de code=0).
(La valeur 1 n'est pas utilisée, pour 3 raisons : l'une pour réserve en début de table, l'autre pour rester simple en ce qui concerne les 3 valeurs identiques sur une même ligne, et la dernière concerne les différents langages qui ne démarrent pas tous les tableaux à l'indice 0, mais souvent à 1)
Voir le fichier ci-dessus pour mieux saisir la difficulté à extraire ce qui est réellement utile et "noyé" dans les codes de champs.
4.3 Le dépouillement des données
Il est identique au début à la macro précédente, à la différence près qu'il ne faudra plus compter sur la transformation en TXT pour obtenir l'adresse IP, puisque les données de PROV/PAGES seraient elles aussi transformées.
Un choix de séparateur va se porter sur le caractère 207 (ALT+207 ¤) qui sera utilisé durant presque toutes les recherches, à cause du point-virgule utilisé par certains moteurs (Yahoo)…La transformation en point-virgule sera rétablie tout à la fin pour des questions de simplification de séparateur d'importation.
Noter que les 2 caractères 124 (ALT+124 ||) restent utilisés pour séparer provenance et destination et qu'ils sont interdits d'utilisation dans les titres (2 caractères 124 consécutifs).
La principale difficulté consiste à éliminer les codes de champs tout en gardant ce qui est réellement utile.
Je passe rapidement sur le critère de recherche de début qui est INCLUDEPICTURE et MERGEFORMATINET pour la fin. Ce dernier élément va permettre de traiter les pays, les O/S et les Navigateurs.
Après il va falloir traiter le cas de l'adresse IP en s'appuyant sur "HYPERLINK" et le "&IP=adresse IP.
Le retour ligne imposé avait déjà été remplacé par les 2 caractères 124 (||). A ce stade il reste les deux HYPERLINK de PROVENANCE et DESTINATION (éventuellement un texte seul avec "Provenance inconnue")
L'élimination des codes de champs se réalise dans la routine ZTraitelignes, qui ne garde :
Pour la Provenance, que ce qui commence par "http ou www jusqu'à slash (/). Ceci représente l'URL d'origine, avec tous les paramètres d'appel. Cela est trop spécifique à dépouiller puisque cela représente la méthode utilisée par chaque moteur pour faire des recherches. Cela ne servirait de plus à rien.
Il est donc préférable de se reporter à ce qui se trouve juste après :"En provenance de : ", et de s'arrêter au premier slash (/) rencontré. La suppression du code de champ complète se fera jusqu'à : \t _blank" et le code de flag final du champ (}).
Ainsi après passage dans ZTraitelignes chaque ligne a  la structure suivante.
la structure suivante.
On ne gardera que les zones en rouge (Altavista par exemple pour la provenance) sans réduction de taille et contenant le dernier suffixe (.com dans l'exemple), mais pour regrouper par exemple tous les Google (.fr, .com, .de etc), il est possible de laisser en table simplement "google". La comparaison fonctionnera aussi bien pour toutes les entités de Google, mais cette fois sans pouvoir les différentier …!
La recherche pour les pages fonctionnera suivant le même principe, puisque là aussi la taille de comparaison sera donnée par la longueur de la zone de comparaison en table. Il faut remarquer que sur cette partie vous êtes directement le responsable des titres, alors que pour les provenances vous devez les "subir".
Pour le dépouillement des pages visitées, il y avait aussi deux solutions, qui étaient de traiter avec le http débutant le champ ou d'aller jusqu'à \o " où l'on retrouve le titre exact de l'article et qui se termine aussi par \t _blank" et le code de flag final du champ.. J'ai donc choisi cette dernière solution qui permet d'éviter la correspondance entre les N° de page Canalblog (adresses URL) et les titres d'articles.
On remarquera que Canalblog ajoute le nom du blog (qui ne participera pas à la comparaison). Dans cet exemple, " - BRICOLSEC" a été ajouté.
4.4 Les améliorations
Une nouvelle provenance non répertoriée en table provoque un code 0 en "provenance" sans arrêter la conversion. Ce n'est pas trop facile de localiser dans le fichier BLOGSTAT.TXT, et encore moins de retrouver la raison puisque les éléments ont disparu à cet instant.
Il a donc été nécessaire de sortir quelques éléments permettant de s'y retrouver sans repasser à chaque fois en Debug.
Toutes erreurs de ce type et les absences de code de conversion des images pays, O/S, et Navigateur, ainsi que les absences de correspondances pour provenance et pages sont mises dans le fichier BLOGTEMP.TXT, qui à ce moment n'est plus utilisé, et qui reste ouvert jusqu'à la fin.
Une acceptation du code (\") est réalisée pour accepter le caractère double quotte (") dans les titres d'articles de blog, mais il faut l'éviter car on perd un peu de temps en traitement et on se plante régulièrement pour le mettre en table !
Ainsi l'entrée de cette valeur en table sera doublée (comme en basic standard) pour éviter qu'elle ne fasse une erreur en interpréteur ou compile. Remarquer que la comparaison se réalise toujours sur un seul (").
Les 2 caractères du code de blog peuvent être rentrés en minuscules et il seront réécrit en majuscules dans le fichier de sortie.
La Table des Pages est RIGOUREUSEMENT le TITRE de l'article. Cependant ce titre peut être tronqué (écourté) s'il n'y pas de risque de confusion possible. C'est la longueur de la ligne de comparaison en Table qui dirigera la longueur de comparaison.
J'espère que les puristes me pardonneront un ou deux goto qui traînent et qui arrangent bien. (Je réalise un outil, mais pas une performance !)
Je viens de modifier la comparaison sur les Pages pour n'être faite que sur la longueur en table et non sur la valeur complète. (comme pour la provenance).
4.5 Le déroulement des opérations
On copie comme pour la version simplifiée date et heure jusqu'aux données précédemment traitées, avec CTRL+C, CTRL+V.
On lance ensuite la macro A_MACRO_BLOG2 avec en première question l'entrée des deux caractères d'abréviation du blog concerné.
Au niveau de la macro, un certain nombre d'opérations ne sont pas toutes exactement identiques et il a été parfois nécessaire de prendre la routine de recherche complète (fonction recherche de Word et non "Rechcar") pour une question de caractères génériques ou spéciaux. Tant pis !
Les routines Rechcar, Recgrepcar, Replaceeol et Ztraite_lignes sont nécessaires au fonctionnement.
Un des problèmes rencontrés et le passage en mode codes de champ ou non.
Rappelez vous que c'est avec ALT+F9 que vous pouvez simplement changer (switch) cette particularité d'affichage. Dans le programme on le réalise par le menu "options". Si vous copiez et si le tableau a une allure "effrayante" à l'écran, pas de panique, ALT+F9 et tout revient identique à chez Canalblog.
Pour la reprise éventuelle, beaucoup de points délicats font l'objet d'un commentaire que j'ai parfois apprécié moi-même, alors pour vous ce sera encore mieux !
Voici l'ordre de déroulement des principales actions :
- Prise du code blog, passage en majuscules.
- Sauvegarde de ce qui est à l'écran en BLOGESS.DOC dans le répertoire en cours;
- suppression de la colonne résolution écran (c'est plus facile à réaliser en mode tableau)
- Passage tableau en texte avec utilisation du code 207 (ALT 207) en séparateur
- Passage en affichage codes de champs
- Recherche dans tout le fichier chaque ligne de TBL et remplacement par le code correspondant
- Ajout du code de blog en colonne 4
- Remplacement du retour ligne imposé de la colonne Provenance/Page par ||
- élimination du dernier return toujours généré par WORD.
- Recherche élimination champ des Hyperlink des adresses IP (conservation IP seule)
- Introduction de l'année complète sur 4 chiffres (nécessaire pour ACCESS)
- Boucle de recherche Provenance et Page, tout le reste étant traité.
- ouverture fichier BLOGTEMP.DOC
- Appel Z_traitelignes qui ne garde que le nécessaire en Provenance et Pages.
- (la suppression des "http.. et des www est réalisée juste avant Z_Traitelignes en global)
- Suppression des espaces excédentaires et des / de fin URL
- Stockage en Fullline$ de la chaîne complète de la ligne dépouillée
- Traitement pour provenance
- Correction anomalie \"
- Traitement Pages
- Examen des erreurs et écriture ligne à ligne en BLOGTEMP.
- Remplacement de tous les espaces par rien
- Remplacement de tous les ALT 207 par des POINTS-VIRGULES
- Sauvegarde du résultat en, BLOGSTAT.TXT et fermeture.
- Visu de BLOGTEMP.DOC et question si sauvegarde à faire
- Réouverture de BLOGSTAT pour présentation résultat et corrections éventuelles.
- Répondre Texte brut (bien que ça marche aussi en codé)
- Basculement en mode affichage SANS codes de champ.
- Message Fin de traitement
ATTENTION Comme pour la première version, pour entrer en importation sur ACCESS, vous devrez fermer impérativement BLOGSTAT.TXT, car ACCESS en importation n'admet pas, même en lecture seule, de concurrence.
4.6 La mise en place de la macro
Je ne vais pas me répéter, c'est exactement la même chose que dans la version simplifiée.
Comme pour l'autre macro, voici le lien pour le téléchargement.
Les subroutines nécessaires sont Rechcar, Reprechcar, Ztraite_Lignes,Replaceeol, et la routine principale A_MACRO_BLOG2. Tout cela se trouvant dans le .TXT à télécharger.
A_MACRO_BLOG3. (Téléchargement au format TXT Version 6 du 10/06/2008)
Le délai de bon fonctionnement ayant été respecté, vous pouvez charger cette version complète. Si vous avez des questions, je reste à votre écoute.
Vous pourrez à priori charger cette nouvelle macro sans problème avec l'ancienne toujours présente, qui ne possédait aucune subroutine. Ainsi vous avez les deux possibilités, exactement comme je suis actuellement.
4.7 ACCESS
Là, cela mérite une petite explication et quelques exemples.
Il faut bien arrêter de croire à la génération spontanée, cela n'existe pas. Ainsi la place importante gagnée en stockage a une contrepartie qui est de représenter les données Provenance/Pages et les autres sous une forme numérique réduite.
Il faudra donc créer dans ACCESS, des tables identiques à celles de la macro (c'est le revers de la médaille !) et faire les liens pour représenter chaque ligne avec tous ses arguments en clair. Cela est typiquement le principe d'une base de données relationnelle. (Ça n'est pas obligatoire mais seulement évident)
Il y aura donc une table Provenance qui sera à mettre à jour en même temps que la macro, et également une table des Pages (idem). Les autres tables existant déjà dans la version simplifiée.
Encore une information. Si vous trouvez que c'est trop compliqué, vous pouvez toujours débuter avec la version simplifiée et évoluer avec la nouvelle version. La base de données ACCESS pourra être corrigée sans problèmes en insérant deux champs de 4 caractères de provenance et Pages, ou même plus simplement en renommant les deux existants si vous ne les avez pas encore utilisés (ce qui était mon cas)
J'ai évolué ainsi simplement, de la version simplifiée à la version Complète. Vous pourrez tout autant procéder ainsi.
Les manques d'entrées en tables SUR LA MACRO se signalent d'eux-mêmes en fin de macro !
Il serait vain de vouloir rechercher manuellement dans ACCESS des anomalies, car en quelques jours, la table BLOGSTAT contient déjà 2600 lignes total et 576 en 3 jou rs1/2 avec la nouvelle macro.
rs1/2 avec la nouvelle macro.
Il faut noter que le plus important est de bien tenir à jour la table des MACROS, car la conséquence serait une perte de l'information, ce qui n'est pas le cas avec les tables ACCESS qui peuvent toujours être reprises ultérieurement, car le code est présent, seul son développement en clair n'est pas réalisé.
Anecdote :
Suite à quelques confusions, certains codes n'étaient pas corrects, et vu la quantité à corriger, il était impossible de faire manuellement. Aussi si certains codes sont erronés, il ne faut pas hésiter à faire une requête action (en ayant fait une sauvegarde) pour remettre tout en ordre.
4.8 Quelques exemples sur ACCESS
4.8.1 Nouvelles Tables ACCESS
BLOG_PAGES, Table à 2 entrées, une sur le code et l'autre sur le développement en Alpha.
Il suffit de lier les valeurs de codes et de ne mettre dans la requête que la deuxième colonne Alpha, pour avoir toute la compréhension de la liaison.
BLOG_PROV, Table à 2 entrées également de structure tout à fait identique à la précédente.
Ce sont les deux ajouts de cette version améliorée.
(Toutes les tables on une jointure qui est dirigée de BLOGSTAT vers les autres tables)
4.8.2 Requêtes
 ACCESS
ACCESS
Quelques exemples de requêtes permettent de voir une présentation des résultats suivant différents critères. Les feuilles de requêtes sont présentées en lieu et place du SQL qui est un peu indigeste aussi, accompagnées d'un exemple portant sur mes deux blogs.
Tous ces exemples comportent la feuille de la requête associée à une partie de résultat en dessous. Je profite de l'occasion pour vous faire remarquer la position des flèches de jointures entre les différentes tables, ainsi que rappelé au paragraphe ci-dessus.
Vous pouvez par exemple créer une table de surveillance dans laquelle vous placerez les différents critères de visite que vous voulez suveiller. Tout est possible !
4.8.3 Requête de recherche d'erreurs ou d'oublis
 Cette petite requête (BLOG_RECH_ERR) va permettre de retrouver les oublis de traduction des codes pour la provenance, les pages ainsi que les conversions d'images. (L'ensemble des oublis est groupé). Il suffit de regader la colonne manquante associée à son code pour comprendre le manque.
Cette petite requête (BLOG_RECH_ERR) va permettre de retrouver les oublis de traduction des codes pour la provenance, les pages ainsi que les conversions d'images. (L'ensemble des oublis est groupé). Il suffit de regader la colonne manquante associée à son code pour comprendre le manque.
Ici la provenance est OK, par contre il manque la dénomination du "NIcaragua" dans la table et le titre corespondant au code 423 (C'était le Silence du pompage de l'eau). (J'ai volontairement fait ces erreurs et elles ne figurent plus dans les tables)
4.8.4 Requête de recherche des dernières données entrées
Cette requête BLOG_LAST_DATE est à lancer avant de rapatrier des données depuis Canalblog. Elle vous indique les dernières valeurs prises en compte. Vous devrez alors tout sélectionner ce qui est supérieur en date+heure sur Canalblog, pour avoir une suite continue sans manques ni doublons.
Elle est pesque inchangée par rapport à la version précédente (voir § 2.5.1) J'ai seulement ajouté le tri sur la colonne Blog pour avoir toujours le même blog en tête et pas seulement la plus petite date+heure. C'est plus pratique.
5 Conclusions de la version complète
Ce sujet a évolué rapidement et les exemples aussi. Seul l'esprit, les principes généraux et la présentation sont importants.
Maintenant que suis arrivé à la fin du sujet, vous pourriez me reprocher de ne pas avoir mis les tables dans un fichier TXT séparé de la macro… Vous avez sans doute raison, mais au moins on a tout en un seul "package" et c'est plus simple à mettre en place. Pour les puristes il ne tient qu'à vous de reprendre la version actuelle, pour moi j'arrête là, cette fois c'est certain.
Dans cette optique de fichiers externes il faudrait vraisemblablement s'embêter avec des tableaux dynamiques, faire les lectures des fichiers, analyser… et je capitule !
A ma connaissance, il n'y a pas d'autres tentatives de ce type, pour le modèle standard (modèle normal) et avec la gestion locale de type Office.
J'ai vu de nombreuses références sur le sujet, mais plus en termes de performances individuelles de blogs que de modèles techniques de réalisation de statistiques.
Je pense que cela intéressera les blogueurs attachés au modèle de base Canalblog, comme moi, et qui n'ont pas volonté à se lancer dans l'aventure d'un modèle non standard.
Il faut dans cette optique seulement connaître un tout petit peu la bureautique, avec ACCESS et WORD, ce que beaucoup d'entre nous maîtrisent.
Cependant, je dois moduler mes propos de traitement possible avec EXCEL, pour cette version améliorée, car les fonctionalités d'EXCEL ne sont pas réellement adaptées et on perd ainsi tout le bénéfice des croisements de données possibles. En ce sens c'est un peu dommage d'avoir tout sous la main et de ne pas en profiter.
Je ne pensais pas réaliser cette version améliorée, mais finalement j'ai eu des remords de ne pas affronter quelques difficultés…Alors, j'ai découvert des visites que je n'avais pas appréhendées. Cela m'a permis notamment de voir quels sont les visiteurs réguliers en quête de nouveautés ou les "accidents" de recherche.
Cela m'a permis de voir, lors des erreurs affichées sur des provenances qui ne sont pas en table, et qu'il y a beaucoup de visiteurs peu connus.
Cela m'a aussi permis de me lancer dans le debug VBA que je ne connaissais pas...Quels progrès et facilités par rapport au debug MS-DOS ! Là je dois reconnaître !
L'expression des résultats sous ACCESS permet surtout de lever le doute sur les meilleurs contributeurs de lecture de blog… (Chut …)
Il faut espérer que Canalblog ne change pas trop vite sa présentation, mais comme les "Stats" détaillées datent d'environ une année, j'ai une relative confiance…
Je ne vais pas faire un deuxième article de cette version complète, car cela ressemblerait à du "remplissage", aussi cette version améliorée qui répond au même titre de "STATISTIQUES" que la précédente, trouve naturellement sa place dans cet article.
Bien entendu, je pense que seuls les blogueurs de Canalblog sont les premiers intéressés à cet article, mais…tout compte fait, le principe général peu être repris pour d'autres types de pages WEB, et cela pourrait servir aussi dans d'autres applications similaires…
Bonne implémentation à ceux qui sont intéressés.
6 Quelques Résultats
Les statistiques sans en tirer des enseignements ne servent à rien. Aussi il était nécessaire de comprendre comment se déroulaient les accès au fil des heures de la journée, mais aussi au fil des jours de la semaine.
J'ai donc exploité mes relevés pour arriver aux deux courbes ci-dessous.
La courbe du nombre de pages vues fonction des plages horaires cumule les deux blogs bricolsec et lokistagnepas. Cette courbe donne le nombre de pages vues par tranches horaires d'une heure. Le nombre d'échantillons est très élévé puisqu'il est de 6833 pages vues, du 7/04/2008 au 14/05/2008.
Concernant l'activité en fonction des jours de la semaine, j'ai séparé les deux blogs car les publics sont sensiblement différents. "bricolsec" concerne plus le bricolage et est destiné à tous, alors que "lokistagnepas" est plus accédé par les professionnels de l'eau potable. Ces résultats portent sur les dates du 4/4/2008 au 25/5/2008
On constate effectivement que la partie professionnelle chute beaucoup plus fortement le Samedi, ce qui est parfaitement logique.
Mais on constate aussi un regain le dimanche au calme, là où les problèmes de la semaine peuvent être réexaminés sereinement. Les valeurs sont exprimées en pourcentage du total des accès de pages.
Les dimanches soirs et lundis sont en général les périodes d'activité les plus importantes. On peut voir également le creux du déjeuner de midi et la fin de la soirée à partir de 22 heures. Un découpage plus fin permettrait certainement de voir les différents horaires de travail... et bien d'autres choses aussi !
Pourquoi cela était important de réaliser ? Tout simplement que pour arriver à ces données, il m'a été nécessaire de stocker régulièrement les statistiques, et que la prévision de pointes de visites est importante. Cela ne m'a pas empêché d'avoir été débordé deux fois lors de pics et d'avoir perdu quelques données. je profite de l'occasion pour dire que 100 résultats stockés, c'est vraiment peu, mais que c'est vrai que la gratuité a un prix !
Outre ces résultats généraux qui peuvent s'appliquer de façon générique plus ou moins précise à tous les blogs, j'ai aussi pu voir quels étaient mes meilleurs contributeurs, et voir aussi quelques sites très secrets qui ne font que passer une fois mais qui vous répertorient sans que vous le sachiez vraiment.


.
7 Suivi des Modifications
Il ne pouvait y avoir d'article sur un sujet informatique sans qu'il y ait un petit suivi des problèmes rencontrés. Voici donc les premières modifications avec la version, et le(s) problème(s) corrigés.
Pour vous repérer dans la version, celle-ci est incluse en commentaire dans la SUB() A_MACRO_BLOG2.
Pour télécharger la nouvelle version (pas d'autre possibilités) reportez vous au paragraphe 4.6 Chargement de la MACRO. Ce chargement sera toujours à la dernière version connue.
Il est également évident que dans ce mode de fonctionnement, je ne conserverai pas de trace des versions précédentes.
J'attire votre attention sur un point qui va vous gêner, qui est que vous n'avez pas les mêmes visiteurs ni les mêmes articles que moi. Aussi il vous sera nécessaire de copier préalablement vos tables (Tblprov(n) Tblprovm(n), TBLPAGESN(n), TBLPAGES(n) ainsi que la table TBL(ZONE1,n) en sécurité dans un autre fichier, puis de les coller par dessus les miennes dans la macro. Vous n'oublierez pas de reprendre les constantes de valeurs max des tables.
Tout est dit voici le premier problème.
_______________
UPDT1, Version 4 : Apparition en Provenance de www5.google.fr . Ce cas du 5 après les www n'était pas prévu.
Il est simplement nécessaire de rentrer en table des provenances "www5.google.fr", puisque la suppression des "www." comporte le point juste après (www5.) et que celle-ci n'est donc PAS réalisée. C'est mieux ainsi que de voir un 5 en tête d'URL qui se promènerait on ne sait d'où.
Toujours sur cette nouvelle version, le N/A sur le pays n'a pas été réellement vu au niveau BD, et comme le pays est codifié en 2 caractères, il y a erreur dans ACCESS par troncature.
Le mieux pour répondre à cela est de reprendre tous les N/A et de les transformer en N/. Cela d'ailleurs devra être équilibré dans ACCESS où je n'avais pas encore traité ces cas. Il n'y aura pas de problème avec le pays puisque N/ n'est pas un pays connu. Pour les autres O/S et Navigateur pas deproblème non plus.
Noter que le critère ";N/A" est utilisé et est nécessaire pour corriger deux N/A qui pourraient se suivre. Un critère plus restrictif empêcherait la modification du deuxième.
Cette modification est réalisée juste après la remise en ordre des ALT+207 par les point virgules, et coûte une seule ligne de modif.
Comme cette modif est très petite, si vous ne voulez pas tout recharger il suffit d'ajouter l'instruction en rouge vers la fin de la macro principale en fin de boucle N1 :
' ------------------------------------------------------------- fin
Call replaceeol(" ", "")
Call replaceeol("¤", ";") 'remplace le code 207 par ;
Call replaceeol(";N/A", ";N/") 'remplace N/A par N/ surtout utile pour les Pays
Selection.EndKey Unit:=wdStory 'enleve return en trop a la fin
N'oubliez pas de corriger aussi la version dans la Sub en 4 c'est mieux ! Cette simple adjonction vous évitera de tout recharger.
UPDT2, Version 5 : Décidément il n'y a de problèmes qu'avec google...Cette version qui n'en est pas une en réalité est juste une information.
google nomme ses différents sites en google.com ou google.ch etc...ou google.co.ma, mais il y en a un qui vient de passer au travers des tables sans faire d'erreurs !
Cela est dû au fait de l'ordre des provenances qui sont recherchées en table. En effet :
Rien ne ressemble plus au début de :
google.com
que google.com.mx (mexique)
Alors évidemment si la table indique google.com en premier le mexique est simplement vu comme google.com puisque c'est la longueur en table qui détermine la longueur de comparaison !
Une solution est de placer google.com en fin de table et de laisser quelques places avant pour ce cas particulier.
Une autre solution est de faire les contrôles avec le / en plus, mais cela oblige à "trainer" ce caractère inutile partout !
Comme je ne veux pas tout renuméroter, ni ajouter partout le /, je laisse ainsi : google mexique passera en google standard !
Je joins la nouvelle version pour la règle, mais NON CORRIGEE.
______________________________
UPDT3, Version 6 : Dernier problème rencontré en Juin 2008, des adresses IP de la forme : 10.81.2.38:15871, cela ne cause pas directement de problème, hormis que derrière cette valeur il y a tout un tas de praramètres qui ne font pas partie du contrôle. Cela induit une erreur dont je ne peux même pas affirmer l'origine. Toujours est-il que dans ce cas spécifique il manque un espace ajouté habituellement par WORD.
Je suppose que cette forme d'IP représente des sous ensembles, mais je n'en avais jamais vu !
La parade consiste à rechercher le caractère 207 et de ne plus compter les "flèches à droite".
J'ose espérer cette fois que l'on arrive vers la fin des cas particuliers qui se déclarent deux mois plus tard tout de même.
Le fichier A_macro_blog3.txt contient la mise à jour et les dernières valeurs rencontrées en termes de recherche et de pays. (Le charger depuis le point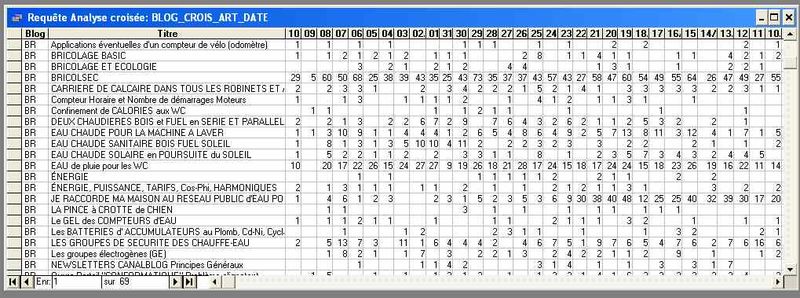 de chargement prévu au paragraphe 4.6)
de chargement prévu au paragraphe 4.6)
Pour donner un aperçu des possibilités générales, (sans rapport avec cette correction) voici un exemple de tableau croisé qui permet réellement de bien peser les articles qui intéressent les internautes. En X les jours depuis le 10 Juin 2008 et en Y quelques titres d'articles. Cela permet réellement de suivre correctement ce qui se passe. On peut même y voir la panne du 9.
UPDT4, Version 6 : Ce n'est pas une erreur, la version n'a pas changé. Il s'agit juste d'une information. Suite au passage en SP2 sur windows XP, (cause Norton qui réclame le Service Pack2 pour XP), le fonctionnement est un peu erratique suivant le nombre de lignes dans WORD. Le système retourne souvent à Canalblog et laisse en (arrière) plan les travaux sous word. Il suffit donc de reprendre dans la barre inférieure d'état chacun des fichiers word (BLOGTEMP et BLOGSTAT) et de répondre aux questions.
J'ai remarqué une accélération très sensible sur Internet et un ralentissement sur WORD dans ce cas (relativement au passage en SP2).
Pour le reste, mes statistiques me conviennent bien. Conviennent-elles à tous ? c'est moins sûr, car depuis le début de l'article j'ai constaté seulement 14 passages...et aucune question.
Je pense que je ne vais plus "user le soleil", sur ce sujet qui me semblait cependant très instructif sur les visites, sauf à titre perso pour maintenir mon outil mais sans le travail de publication...
UPDT5, Version 6 : (correspondant à V5 du titre) Là aussi ce n'est pas une erreur, la version ne change pas ! Il s'agit juste d'une information.
La création des TAG a sensiblement fait évoluer le champ "origine" transmis par CB dans le tableau des derniers accès.
Ainsi dans l'origine, on retrouve maintenant le mot du TAG avec le nom du blog. Pour palier ce problème, il suffit de rajouter un ligne dans la table provenance de la macro et de pointer sur le nom général de l'article correspondant.
Néanmoins cela appelle plusieurs sommentaires :
Cette opération augmentera sensiblement les temps de traitement et la gestion sera d'autant plus lourde qu'il faudra faire souvent des mises à jour des tables.
Les tags ne sont pas anodins et amène effectivement des consultations. Si l'on fait des statistiques complète comme c'est mon cas, il y nécessité de parfaitement les cibler, sous peine de se retrouver avec des montagnes de mots qui convergent vers un article.
Pour des sujets voisins, il est certain que les tags peuvent étouffer d'autres articles. Il y a donc lieu d'utiliser ces éléments avec discernement et de ne pas tout mettre. J'envisage plus de mettre un maximum de tags sur la page d'accueil que sur un article particulier (ou de parfaitement le cibler).
Je vais donc faire machine arrière sur les TAGS et mieux repenser mon affaire.
Il est même possible que les tags perturbent certaines pages avec du code html "un peu exotique", par les codes ajoutés ? (c'est une supposition)
UPDT6, Version 6 : Sans aucun changement de version...
J'abandonne la méthode car la gestion des informations recueillies m'a amené un trafic plus important et du fait de la limite aux 100 dernières visites, je ne fais plus qu'enregistrer les données...!
Ce n'est donc plus vivable et je le regrette, car l'exploitation fine des visiteurs permet de très bien cibler ses articles et d'orienter son action pour une meilleure audience.
Dois-je encourager ceux qui débutent un blog à ne pas le faire ? Certainement pas. Je les invite au contraire à utiliser cette méthode. C'est très instructif, et ça les aidera beaucoup, surtout au début.
Après ce serait tout aussi important, mais ça ne pourrait plus être géré.
Je pense cependant continuer par "prélèvement", mais sans toutes fois garantir l'absence de manques.
Je regrette seulement l'étroitesse de stockage de CB mais je ne peux pas blâmer ce qui est gratuit ! Bonnes STATS à toutes et tous.
Je vais donc me replier sur les visiteurs et pages vues par jour, où là le stockage est sur une année complète. Là il y a de la marge, mais avec une perte considérable d'informations !
UPDT7, Version 6 : Sans aucun changement de version...(09/12/2008)
Dernière Mise à jour pour deux raisons :
La première est que je viens de vérifier qu'il y a quelques messages qui peuvent être doublés, mais pas de la faute de ma méthode. J'ai compris pourquoi, car à chaque page de statistiques, Canalblog ne prend pas les statistiques arrêtées depuis l'appui sur le bandeau "statistiques" ou "derniers accès", mais reprend les valeurs en temps réel à chaque changement de page des stats (c'est donc instable !). Il peut donc y avoir du nouveau entre chaque page et cela se produit quelques fois !
Je ne sais donc pas corriger de façon simple ce problème et je suis obligé de caler sur cette difficulté. Il n'empêche que je continue souvent avec quelques aléas et que cela reste très intéressant.
La deuxième raison est que, à plus de 200 messages par jour, il est très aléatoire d'enregistrer les statistiques de façon fiable... on arrive pas toujours à temps !
Alors j'ai refait un autre macro qui enregistre seulement les valeurs du tableau synthèse, et là on a plusieurs mois pour se retourner, mais il manque naturellement des informations !
8 Un repérage étrange
Le 29/6/2008, en épluchant mes visites, j'ai vu un site inconnu "anonymizerx.merletn.org", (normalement signalé par une erreur dans la macro) mais le nom "me disait quelque chose"...
Après avoir recherché sur CB si ce site avait fait l'objet de quelques infos, je n'ai rien trouvé ! Un site qui a fait plusieurs erreurs de navigation m'intrigue toujour s.
s.
Qu'elle n'est pas ma surprise de voir depuis CB en cliquant le lien, une de mes réponses sur le forum Plomberie PER (sur lequel je participe aux discussions), avec une adresse de renvoi qui passe par ce site cité, et non simplement comme je l'avais saisie dans ma réponse.
J'ai d'abord considéré cela comme une usurpation, mais après essais j'ai compris que merlet est une boîte à lettre pour surfer en ne laissant aucune trace sur le net.
Je ne suis pas très connaisseur sur le sujet, mais il me semble que "merlet", lui, possède toutes les adresses !
A priori il n'y aurait que le "piraté" qui peut voir cette URL déviée...et peut-être celui qui travaille avec ce logiciel qui doit rapatrier tous les fichiers spécifiques pour ne pas laisser son empreinte (certainement avec le "TCP"). En outre quand on regarde son blog au travers de ce site, il y a une bande grise avec ascenseur en haut à gauche (ou en bas de page) avec le nom "Merlet".
J'ai été relire ma réponse directement dans le forum cité, et effectivement pas de problème, c'est bien ma seule URL http://bricolsec.canalblog.com qui apparait à la place de l'autre.
A priori, ce genre de visite est de quelqu'un qui n'a pas le courage de vous laisser son IP.
Je pense qu'il y aurait mieux à faire que de développer et d'utiliser ce genre de logiciel, car c'est un produit qui me parait hyper dangereux.
Voilà pour l'info, et à savoir qu'il y a un chiffre variable qui est sur anonymizer6, car après un autre essai j'ai eu un 8 à la place du 6.
Enfin grâce à ce programme de statistiques j'ai pu rechercher ce site dans mes visites (sans le 6 ou le 8) et j'ai vu que j'étais passé dessus une première fois le 12/6/2008 sans le remarquer, car j'ai eu un 8 au lieu du 6 ! Encore une astuce de site, car pour deux noms différents, j'ai la même IP ! Normal ou Pas ? Le nom général me disait bien quelque chose ! Je n'aurais jamais pu retrouver cela sans les statistiques...
___________________ ( retour début d'article ) ___
____ ( retour bricolsec ) ____
____ ( retour lokistagnepas ) ____


/https%3A%2F%2Fstorage.canalblog.com%2F27%2F68%2F338014%2F134429101_o.jpg)
/https%3A%2F%2Fstorage.canalblog.com%2F85%2F14%2F338014%2F132532468_o.jpg)
/https%3A%2F%2Fp8.storage.canalblog.com%2F85%2F14%2F338014%2F132532468.jpg)
/https%3A%2F%2Fstorage.canalblog.com%2F83%2F66%2F338014%2F131519391_o.jpg)
/https%3A%2F%2Fprofilepics.canalblog.com%2Fprofilepics%2F2%2F8%2F289215.jpg)